前言
RDD 的分区概念在 RDD 概述里已经说过,这里就不在复述
分区
分区数越多,任务数越多,执行效率就高
makeRDD() 分区的体现
使用数组创建RDD,直接保存,我们发现数组里只有 5 的元素,但却输出的 8 个文件。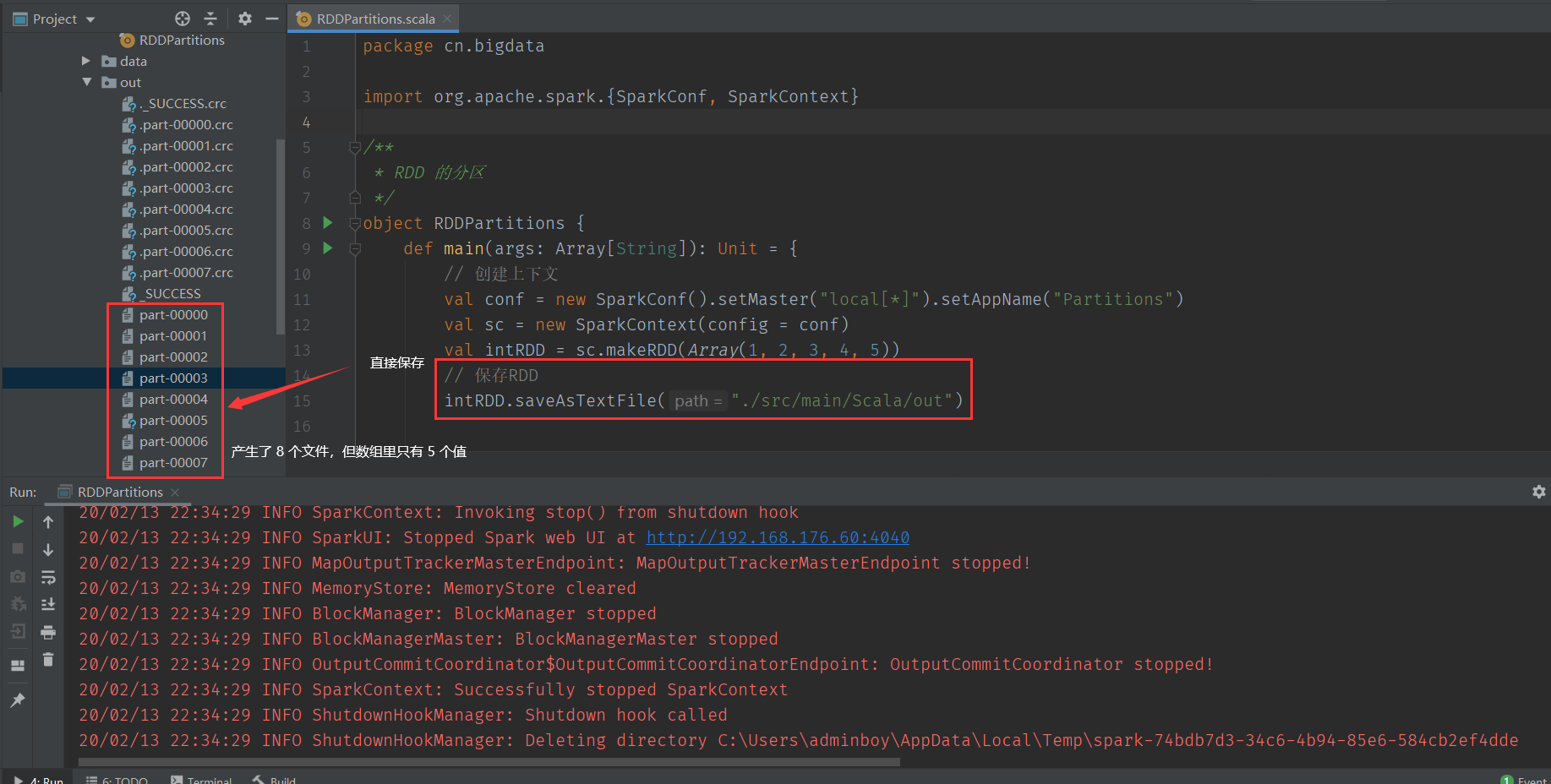
查看 makeRDD() 的源码,发现还有第二个参数
numSlices
这个第二个参数,就是指定切为多少分区。
def makeRDD[T: ClassTag](
seq: Seq[T],
// 注意这里是 numSlices,因为 textFile() 方法有点不一样
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
它的默认值(defaultParallelism)是会去判定你是否设置(conf),否者就去获取全部的 CPU 个数来进行默认设置。
override def defaultParallelism(): Int = {
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
textFile() 分区的体现
同样的保存只产生了两个
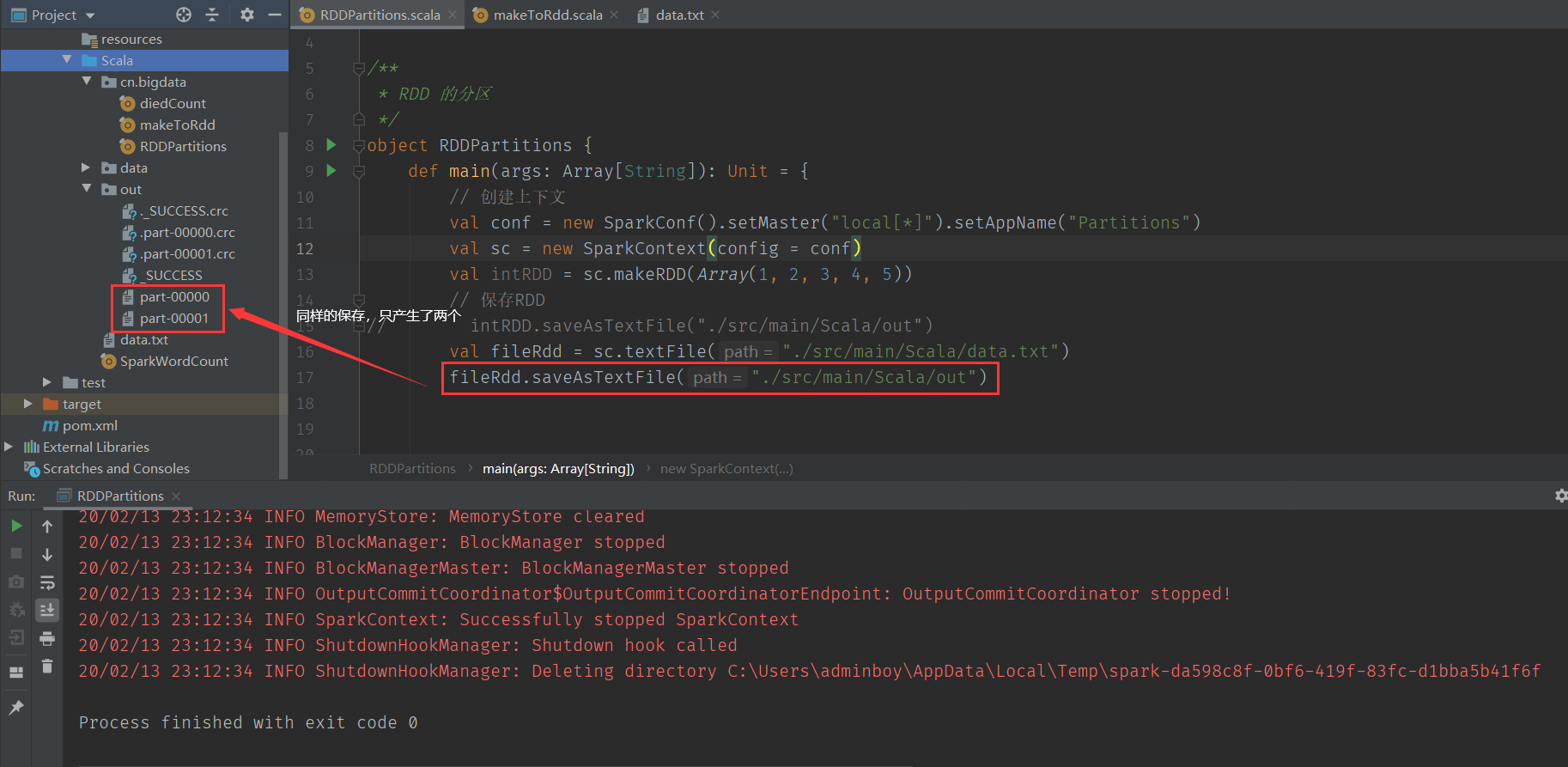
查看 textFile() 的源码,第二个参数是
minPartitions(最小的)
其中调用了 hadoopFile(),所以 Spark 对文件的切分规则跟 Hadoop 是一样的,(所以就会出现一个指定分区为2 ,但实际却有3 的情况,因为分 2 个,还会剩下,所以就会产生大于 2 个)。所以当自定义了分区数,实际情况可能不是这个数
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
继续向下看源码,发现首先获取了配置里参数,然后与 2 作比较,取小的作为默认参数
def defaultMinPartitions: Int = math.min(defaultParallelism, 2)
版权声明:《 Spark RDD 分区 》为明非原创文章,转载请注明出处!
最后编辑:2020-2-13 15:02:40